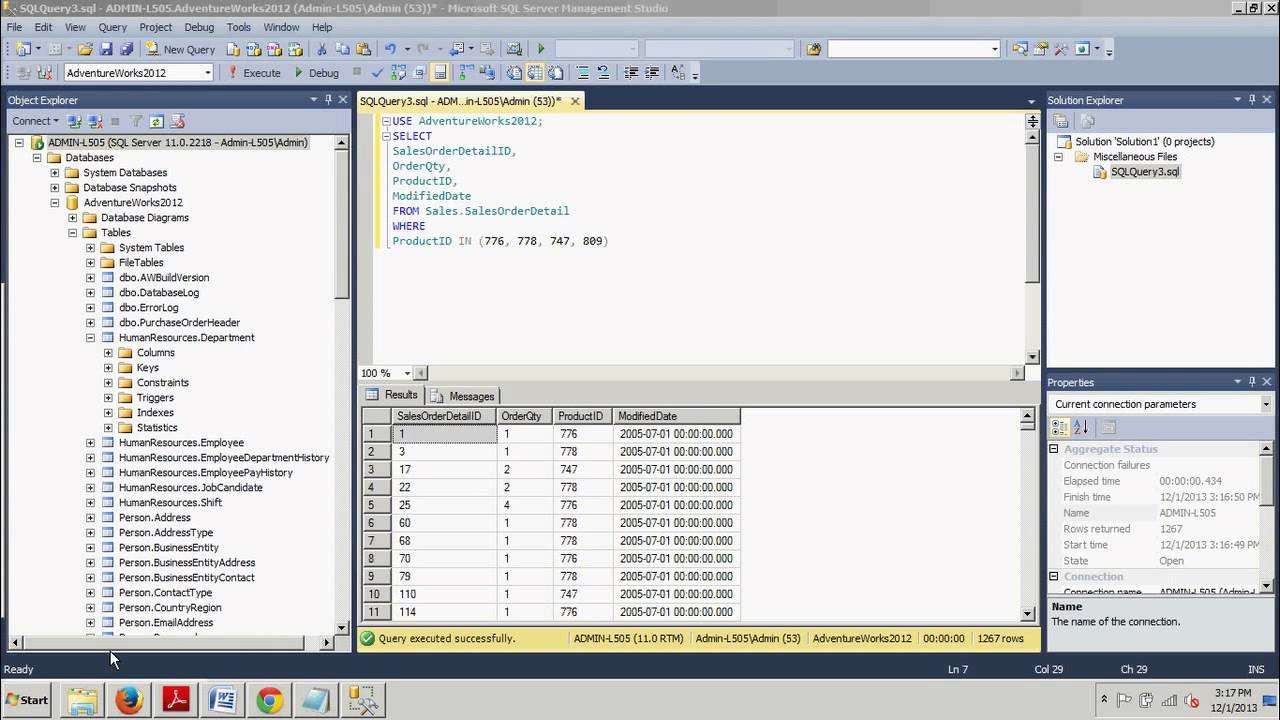
Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause near the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. HAVING condition This is a further condition applied only to the aggregated results to restrict the groups of returned rows. Only those groups whose condition evaluates to TRUE will be included in the result set.

A WITH clause is an optional clause that precedes the SELECT list in a query. The WITH clause defines one or more common_table_expressions. Each common table expression defines a temporary table, which is similar to a view definition. You can reference these temporary tables in the FROM clause. Each CTE in the WITH clause specifies a table name, an optional list of column names, and a query expression that evaluates to a table . When you reference the temporary table name in the FROM clause of the same query expression that defines it, the CTE is recursive.

Though both are used to exclude rows from the result set, you should use the WHERE clause to filter rows before grouping and use the HAVING clause to filter rows after grouping. In other words, WHERE can be used to filter on table columns while HAVING can be used to filter on aggregate functions like count, sum, avg, min, and max. A common table expression is a named temporary result set that exists within the scope of a single statement and that can be referred to later within that statement, possibly multiple times. The following discussion describes how to write statements that use CTEs.
The GROUP BY clause groups together rows in a table with non-distinct values for the expression in the GROUP BY clause. For multiple rows in the source table with non-distinct values for expression, theGROUP BY clause produces a single combined row. GROUP BY is commonly used when aggregate functions are present in the SELECT list, or to eliminate redundancy in the output. A WITH clause contains one or more common table expressions . A CTE acts like a temporary table that you can reference within a single query expression. Each CTE binds the results of a subqueryto a table name, which can be used elsewhere in the same query expression, but rules apply.

In Script #4, I am creating a table-valued function which accepts DepartmentID as its parameter and returns all the employees who belong to this department. The next query selects data from the Department table and uses a CROSS APPLY to join with the function we created. It passes the DepartmentID for each row from the outer table expression and evaluates the function for each row similar to acorrelated subquery.
The APPLY operator allows you to join two table expressions; the right table expression is processed every time for each row from the left table expression. The final result set contains all the selected columns from the left table expression followed by all the columns of the right table expression. SQL Inner Join permits us to use Group by clause along with aggregate functions to group the result set by one or more columns. Group by works conventionally with Inner Join on the final result returned after joining two or more tables. If you are not familiar with Group by clause in SQL, I would suggest going through this to have a quick understanding of this concept. Below is the code that makes use of Group By clause with the Inner Join.

To better manage this we can alias table and column names to shorten our query. We can also use aliasing to give more context about the query results. Programs on client computers allow users to manipulate that data, using tables, columns, rows, and fields.

To do this, client programs send SQL statements to the server. The server then processes these statements and returns result sets to the client program. An ordinary common table expression works as if it were a view that exists for the duration of a single statement. Ordinary common table expressions are useful for factoring out subqueries and making the overall SQL statement easier to read and understand.
Recursive common table expressions are useful for traversing data that forms a hierarchy. Consider these statements that create a small data set that shows, for each employee in a company, the employee name and ID number, and the ID of the employee's manager. All common table expressions are created by prepending a WITH clause in front of a SELECT, INSERT, DELETE, or UPDATE statement. A single WITH clause can specify one or more common table expressions, some of which are ordinary and some of which are recursive. As mentioned previously, recursive common table expressions are frequently used for series generation and traversing hierarchical or tree-structured data. This section shows some simple examples of these techniques.

The GROUP BY clause is a SQL command that is used to group rows that have the same values. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. The ORDER BY clause specifies a column or expression as the sort criterion for the result set. If an ORDER BY clause is not present, the order of the results of a query is not defined. Column aliases from a FROM clause or SELECT list are allowed.
If a query contains aliases in the SELECT clause, those aliases override names in the corresponding FROM clause. A WITH clause can contain ordinary common table expressions even if it includes the RECURSIVE keyword. The use of RECURSIVE does not force common table expressions to be recursive. The OUTER APPLY operator returns all the rows from the left table expression irrespective of its match with the right table expression. For those rows for which there are no corresponding matches in the right table expression, it contains NULL values in columns of the right table expression.

Inner Join syntax basically compares rows of Table1 with Table2 to check if anything matches based on the condition provided in the ON clause. When the Join condition is met, it returns matched rows in both tables with the selected columns in the SELECT clause. The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. The main difference between the WHERE and HAVING clauses comes when used together with the GROUP BY clause.

In that case, WHERE is used to filter rows before grouping, and HAVING is used to exclude records after grouping. This is the most important difference, and if you remember this, it will help you write better SQL queries. This is also one of the important SQL concepts to understand, not just from an interview perspective but also from a day-to-day use perspective. I am sure you have used the WHERE clause because it's one of the most common clauses in SQL along with SELECT and used to specify filtering criteria or conditions.

FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. A common table expression is recursive if its subquery refers to its own name. The RECURSIVE keyword must be included if any CTE in the WITHclause is recursive.

For more information, see Recursive Common Table Expressions. Assume, we have two tables, Table A and Table B, that we would like to join using SQL Inner Join. The result of this join will be a new result set that returns matching rows in both these tables. The intersection part in black below shows the data retrieved using Inner Join in SQL Server.

When referencing a range variable on its own without a specified column suffix, the result of a table expression is the row type of the related table. Value tables have explicit row types, so for range variables related to value tables, the result type is the value table's row type. Other tables do not have explicit row types, and for those tables, the range variable type is a dynamically defined STRUCT that includes all of the columns in the table. The USING clause requires a column list of one or more columns which occur in both input tables. It performs an equality comparison on that column, and the rows meet the join condition if the equality comparison returns TRUE. HAVING and WHERE are often confused by beginners, but they serve different purposes.
WHERE is taken into account at an earlier stage of a query execution, filtering the rows read from the tables. If a query contains GROUP BY, rows from the tables are grouped and aggregated. After the aggregating operation, HAVING is applied, filtering out the rows that don't match the specified conditions. Therefore, WHERE applies to data read from tables, and HAVING should only apply to aggregated data, which isn't known in the initial stage of a query. During the execution of the statement in which it is embedded; it runs before the recursive clause and generates the first set of rows from the recursive CTE. These rows are not only included in the output of the query, but also referenced by the recursive clause.

The SQL WHERE clause is used to specify a condition while fetching the data from a single table or by joining with multiple tables. If the given condition is satisfied, then only it returns a specific value from the table. You should use the WHERE clause to filter the records and fetching only the necessary records.

Well, the main distinction between the two clauses is that HAVING can be applied for subsets of aggregated groups, while in the WHERE block, this is forbidden. In simpler words, after HAVING, we can have a condition with an aggregate function, while WHERE cannot use aggregate functions within its conditions. An INNER JOIN returns a result set that contains the common elements of the tables, i.e the intersection where they match on the joined condition.

INNER JOINs are the most frequently used JOINs; in fact if you don't specify a join type and simply use the JOIN keyword, then PostgreSQL will assume you want an inner join. Our shapes and colors example from earlier used an INNER JOIN in this way. Let me show you another query with aDynamic Management Function . Script #5 returns all the currently executing user queries except for the queries being executed by the current session. The first query in Script #3 selects data from Department table and uses an OUTER APPLY to evaluate the Employee table for each record of the Department table. For those rows for which there is not a match in the Employee table, those rows contain NULL values as you can see in case of row 5 and 6 below.

The second query simply uses a LEFT OUTER JOIN between the Department table and the Employee table. As expected, the query returns all rows from Department table, even for those rows for which there is no match in the Employee table. In this tip I am going to demonstrate the APPLY operator, how it differs fromregular JOINsand some uses. Before we get started with SQL Inner Join, I would like to call out SQL Join here. Join is the widely-used clause in the SQL Server essentially to combine and retrieve data from two or more tables.

There are four basic types of Joins in SQL Server – Inner, Outer , Self and Cross join. To get a quick overview of all these joins, I would recommend going through this link, SQL Join types overview and tutorial. The INTERSECT operator returns rows that are found in the result sets of both the left and right input queries. Unlike EXCEPT, the positioning of the input queries does not matter. Because the UNNEST operator returns avalue table, you can alias UNNEST to define a range variable that you can reference elsewhere in the query.

Why Do We Use With Clause In Sql If you reference the range variable in the SELECTlist, the query returns a STRUCT containing all of the fields of the originalSTRUCT in the input table. SELECT AS STRUCT can be used in a scalar or array subquery to produce a single STRUCT type grouping multiple values together. Scalar and array subqueries are normally not allowed to return multiple columns, but can return a single column with STRUCT type. Query statements scan one or more tables or expressions and return the computed result rows. This topic describes the syntax for SQL queries in BigQuery.
In this lesson you learned to use the SQL GROUP BY and aggregate functions to increase the power expressivity of the SQL SELECT statement. You know about the collapse issue, and understand you cannot reference individual records once the GROUP BY clause is used. This clause is used in SQL because we cannot use the WHERE clause with the SQL aggregate functions. Both WHERE and HAVING clauses are used for filtering the records in SQL queries. The WITH clause, or subquery factoring clause, is part of the SQL-99 standard and was added into the Oracle SQL syntax in Oracle 9.2. The WITH clause may be processed as an inline view or resolved as a temporary table.

You should assess the performance implications of the WITH clause on a case-by-case basis. The with clause is also known as common table expression and subquery factoring. Note that the recursive from of the with clause is covered in another article. The WITH clause is a drop-in replacement to normal subqueries. The only difference is that you can re-use the same derived result set multiple times in your code when you use the WITH clause to generate a CTE.
The preceding subquery uses a correlation name defined in the outer query. The reference, empx.dept, must be explicitly qualified here. Otherwise the dept column is assumed to be implicitly qualified by empy. The overall query is evaluated by assigning empx each of its values from the employee table and evaluating the subquery for each value of empx. If filtering can be done without aggregate function then you must do it on the WHERE clause because it improves performance because counting and sorting will be done on a much smaller set.

If you filter the same rows after grouping, you unnecessarily bear the cost of sorting, which is not used. However, the query optimizer now treats EXISTS and IN the same way, whenever it can, so you're unlikely to see any significant performance differences. Nevertheless, you need to be cautious when using the NOT IN operator if the subquery's source data contains NULL values. If so, you should consider using a NOT EXISTS operator instead of NOT IN, or recast the statement as a left outer join.

Thus far in this chapter, we've looked at using JOINs to work with more than one table. Although joining tables together is probably the most common way of working with multiple tables, you can often achieve the same results through use of a subquery. Before we compare subqueries and joins, let's examine what a subquery is. A FULL JOIN or FULL OUTER JOIN is essentially a combination of LEFT JOIN and RIGHT JOIN. This type of join contains all of the rows from both of the tables. Where the join condition is met, the rows of the two tables are joined, just as in the previous examples we've seen. For any rows on either side of the join where the join condition is not met, the columns for the other table have NULL values for that row.
When there is no match, the corresponding rows will use NULL to represent the missing values. A LEFT JOIN or a LEFT OUTER JOIN takes all the rows from one table, defined as the LEFT table, and joins it with a second table. The JOIN is based on the conditions supplied in the ON clause. A LEFT JOIN will always include the rows from the LEFT table, even if there are no matching rows in the table it is JOINed with.

When there is no match, the corresponding rows will use NULL to represent the missing values from the second table. The "AS MATERIALIZED" and "AS NOT MATERIALIZED" forms of a common table expression are non-standard SQL syntax copied from PostgreSQL. Using MATERIALIZED or NOT MATERIALIZED after the AS keyword provides non-binding hints to the query planner about how the CTE should be implemented. But those are just different syntaxes for saying exactly the same thing. The other change is that the recursion is stopped by a LIMIT rather than a WHERE clause. The use of LIMIT means that when the one-millionth row is added to the "cnt" table then the recursion stops immediately regardless of how many rows might be left in the queue.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.